前面四篇,我们搞清楚了 Agent 的完整工作原理:LLM 负责思考,Tool Use 负责执行,Agent Loop 把它们串成循环,System Prompt 定义行为规则。
但如果你真的跑过一个 Agent,你一定会遇到一个非常现实的问题:跑着跑着,它就“失忆”了,或者直接报错说 token 超限了。
这就是今天要聊的主题,上下文管理。
先搞清楚一个概念:上下文窗口
LLM 不是一个有记忆的东西。前面第三篇我们说过,它是无状态的,每次调用都要把完整的消息历史发给它,它才能知道之前发生了什么。
而这个“完整的消息历史”,不能无限长。每个 LLM 都有一个上下文窗口(Context Window),就是它一次能处理的信息总量上限,单位是 token。
现在主流模型的上下文窗口大概是这样的:
- Claude:1M token
- GPT-5:1M token
听起来挺大的?别急,我们算算 Agent 跑起来会消耗多少。
上下文是怎么被吃掉的
一个 Agent 每跑一轮循环,消息历史里就会多出这些东西:
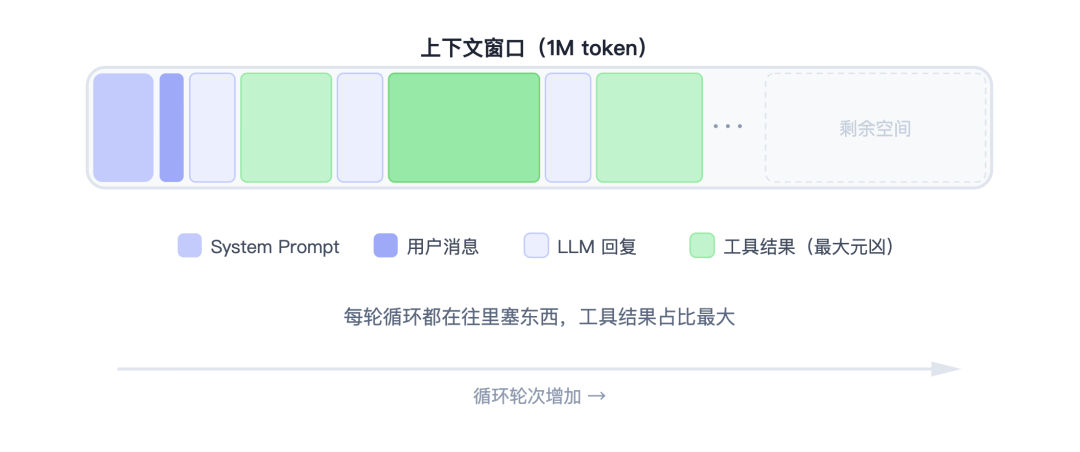
- LLM 的回复(包含思考过程和 tool_use)
- 工具执行的结果(tool_result)
关键是工具返回的结果往往很大。你让 Agent 读一个文件,tool_result 就是整个文件的内容,随便一个代码文件就可能几百行。你让它执行一个命令,输出也可能是一大片日志。
我们来算一笔账。假设 Agent 处理一个中等复杂度的任务,跑了 20 轮循环:
| 内容 | 大小估算 |
|---|---|
| System Prompt | ~3000 token |
| 用户消息 | ~200 token |
| 20 轮 LLM 回复 | ~10000 token |
| 20 轮工具结果 | ~40000 token |
| 总计 | ~53000 token |
这还只是一个中等任务。如果是复杂任务,跑个五六十轮,再读几个大文件,轻轻松松就奔着几十万 token 去了。
而且别忘了,上下文窗口是输入和输出共享的。你输入占了 180K,留给 LLM 生成回复的空间就只剩 20K 了。
这就是上下文管理的核心矛盾:Agent 跑的轮次越多,积累的信息越多,但能装信息的容器就那么大。
为什么不能简单地丢掉旧消息
你可能会想:既然装不下了,把早期的消息删掉不就行了?
没那么简单。
假设 Agent 在第 3 轮读了一个配置文件,到第 25 轮的时候需要根据这个配置来修改代码。如果你把第 3 轮的内容删了,LLM 就不知道配置文件里写了什么,它要么瞎猜,要么重新去读一遍(浪费一轮循环)。
消息历史是 Agent 的“工作记忆”。随便删东西,就像一个人突然忘掉了之前的调查结果,轻则重复劳动,重则做出错误判断。
所以上下文管理的难点在于:怎么在有限的空间里,保留最重要的信息,丢掉不重要的。
常见的管理策略
实际的 Agent 产品会用几种策略来应对这个问题:
1. 对话摘要压缩
这是最常用的策略。当消息历史快要超限的时候,把早期的对话内容“压缩”成一段摘要。
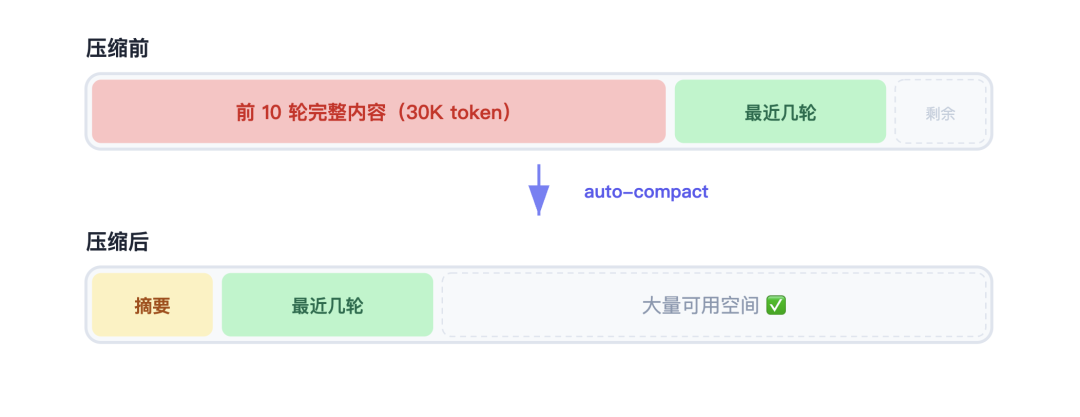
比如前 10 轮的完整对话可能有 30000 token,压缩成一段摘要可能只需要 2000 token:
“用户让我修复 login 接口的 bug。我读了 src/auth/login.ts 和 src/utils/token.ts,发现 token 生成逻辑有问题,已经修复并更新了测试。”
这段摘要保留了关键信息(做了什么、改了哪些文件、结论是什么),但体积只有原来的十分之一不到。
谁来做这个压缩?还是 LLM 自己。你把早期的对话内容发给 LLM,让它生成一段摘要,然后用这段摘要替换掉原来的详细内容。
Claude Code 就用了这种方式,它叫 auto-compact。当上下文快满的时候,自动触发一次压缩,把早期对话浓缩成摘要,腾出空间给后续的工作。
2. 工具结果截断
工具返回的结果往往是上下文膨胀的最大元凶。一个文件内容可能有几千行,但 LLM 真正需要的可能只是其中几十行。
所以可以在返回 tool_result 的时候就做限制:
- 文件太长?只返回前 N 行,或者只返回与当前任务相关的部分
- 命令输出太多?截断,只保留最后 N 行(通常错误信息在末尾)
- 搜索结果太多?只返回 Top N 条最相关的
这种策略的好处是从源头控制输入量,坏处是可能丢掉了 LLM 需要的信息。所以截断要有策略,不能一刀切。
3. 滑动窗口
最简单粗暴的方式:只保留最近 N 轮的消息,更早的直接丢掉。
这种方式实现简单,但效果一般。因为 Agent 的工作往往是有连贯性的,第 5 轮做的事情可能在第 30 轮还有用。单纯按时间丢弃,很容易丢掉关键信息。
所以在实际产品中,滑动窗口通常不会单独使用,而是和摘要压缩配合:超出窗口的部分不是直接删掉,而是先压缩成摘要再保留。
4. 按需重新获取
既然旧的工具结果可以丢掉,那 LLM 需要的时候再重新获取不就行了?
比如第 3 轮读过的配置文件,到第 25 轮如果还需要,LLM 可以再调一次 read_file 重新读。反正工具还在,随时都能用。
这种方式的代价是多消耗一轮循环和一次工具调用,但好处是信息始终是最新的(文件可能在中间被修改过),而且不需要一直把内容留在上下文里占空间。
上下文管理的核心权衡
你会发现,所有策略都在做一个权衡:信息完整性 vs 空间效率。
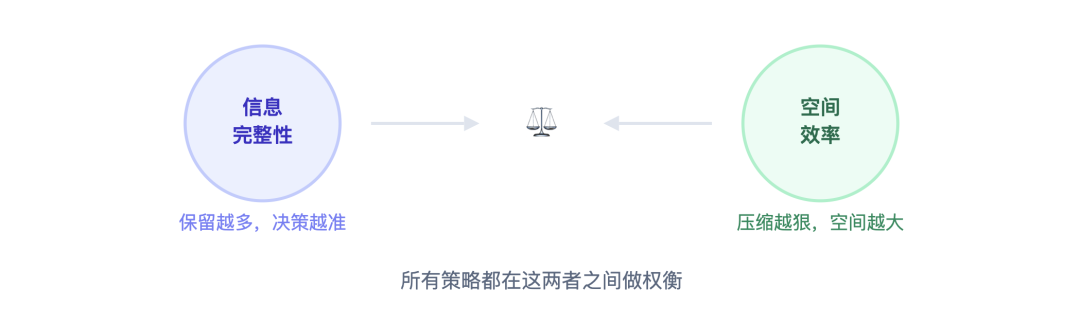
保留的信息越完整,LLM 做决策的质量越高,但空间消耗也越大。压缩得越狠,空间越充裕,但 LLM 可能因为缺少关键信息而犯错。
没有完美的方案,只有适合当前场景的方案。好的 Agent 产品会组合使用多种策略,并且根据实际情况动态调整。
比如 Claude Code 的做法大致是这样的:
- 默认保留完整的消息历史
- 当上下文接近上限时,自动触发 compact(摘要压缩)
- 压缩时保留最近几轮的完整内容,更早的部分生成摘要
- 用户也可以手动触发压缩
这种方式在大多数场景下都能工作得不错。
为什么上下文管理是“能跑”到“能用”的关键
一个不做上下文管理的 Agent,跑个三五轮没问题,但稍微复杂一点的任务(需要十几轮甚至几十轮)就会撞墙。要么 token 超限直接报错,要么上下文太长导致 LLM 注意力分散,开始忽略早期的重要信息。
这也是为什么很多人自己写的 demo Agent 看起来能跑,但真正用起来很快就不行了。差别不在 Agent Loop 的实现上,而在这些“看不见的细节”上。
上下文管理就是这样一个看不见但极其重要的模块。它不决定 Agent 能不能工作,但决定了 Agent 能不能持续、稳定、可靠地工作。
一句话总结
上下文管理就是在有限的空间里,保留最重要的信息,让 Agent 能持续工作。核心策略是摘要压缩、结果截断、滑动窗口和按需重新获取,本质上都是在信息完整性和空间效率之间做权衡。
到这里,AI Agent 的五个核心概念我们就全部聊完了:LLM、Tool Use、Agent Loop、System Prompt、上下文管理。这五个东西组合在一起,就是 Cursor、Claude Code 这些 AI 编程助手背后的完整原理。
理解了这些,你就真正搞懂了 Agent 是怎么工作的。