rosedb 是一个轻量级、快速、稳定可靠的单机磁盘 KV 存储引擎,基于一种日志追加型的文件组织方式。
https://github.com/rosedblabs/rosedb
它足够的简单,每个人都能够轻松理解其运行的原理,它也足够的小巧精悍,能够满足基本的数据存储需求。
无论你是数据库的爱好者、开发者,甚至是基础架构相关的开发,都能够从这个项目中学习到数据库这类系统级项目的基本设计原理和实现细节。
rosedb 基于 bitcask 存储模型,这是由一家数据库商业化公司 Riak 在 2010 年提出来的,相关文章介绍如下:
https://riak.com/assets/bitcask-intro.pdf
Riak 主要是想打造一个全新的存储引擎,在最理想的情况下,满足下面的这些条件:
- 读写低延迟
- 高吞吐,特别是对大量的随机写入
- 能够处理超过内存容量的数据
- 崩溃恢复友好,能够保证快速恢复,不丢数据
- 简单的备份和恢复策略
- 相对简单、易懂的代码结构和数据存储格式
- 在大数据量下,性能有保障
- 能够有自由的授权使用在 Riak 的系统中
在当时已有的存储引擎中,没有一个能够很好的满足这些条件(LevelDB 和 RocksDB 虽然成熟强大,但是过于复杂),于是 Riak 团队重新设计了一个简单、高效的存储引擎 bitcask。
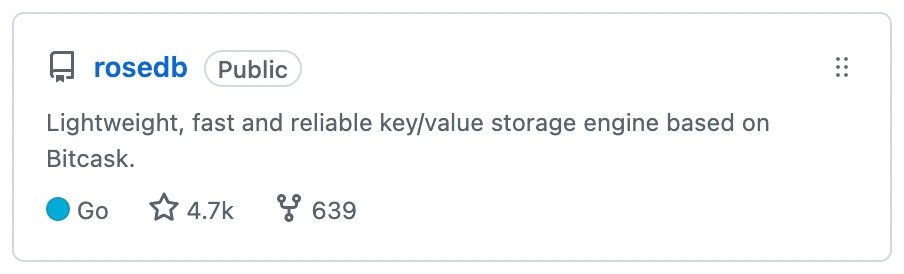
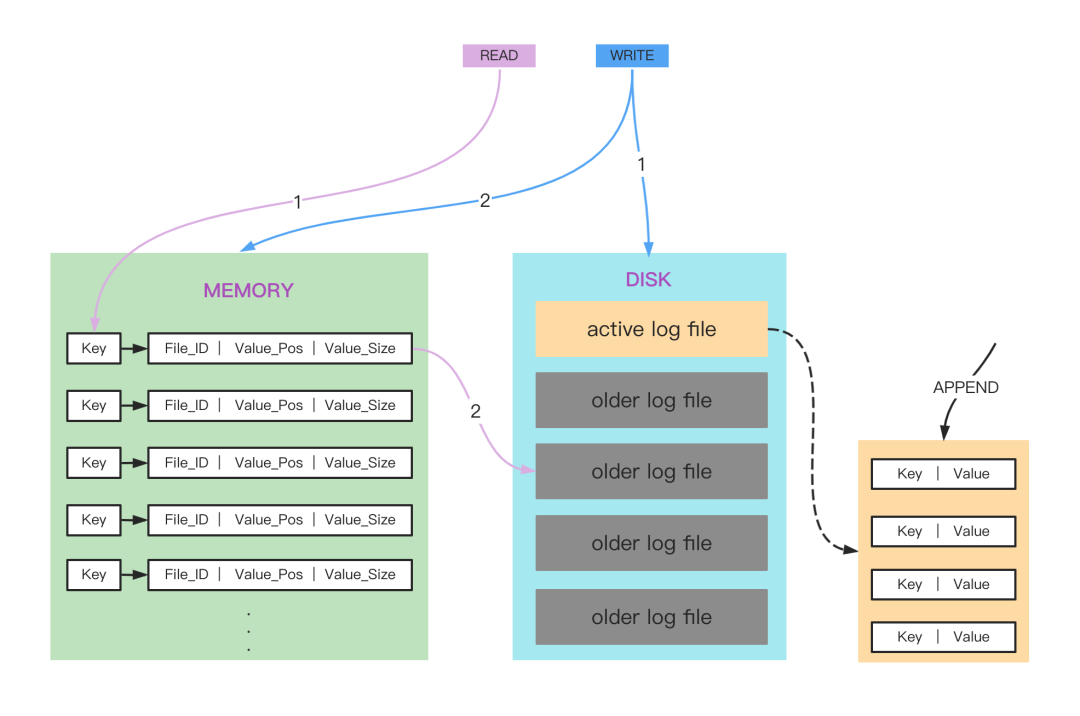
一个 bitcask 实例就是系统上的一个目录,并且限制同一时刻只能有一个进程打开这个目录。目录中有多个文件,同一时刻只有一个活跃的文件用于写入。
当活跃文件写到满足一个阈值之后,就会被关闭,成为旧的数据文件,并且打开一个新的文件用于写入。
所以这个目录中就是一个活跃文件和多个旧的数据文件的集合。
当前活跃文件的写入是只能追加的(append only),这意味着可以利用顺序 IO,不会有多余的磁盘寻址,最大限度保证了吞吐。
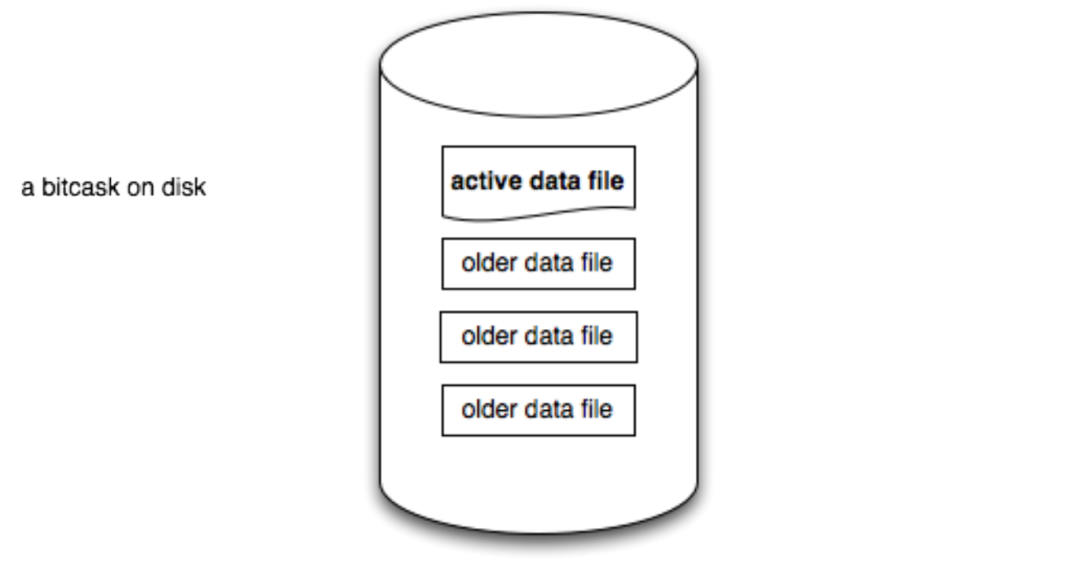
写入到文件的数据,具有固定的格式,大致有这些信息:
- crc:数据校验和,防止数据被破坏、篡改等
- timestamp:写入数据的时间戳
- ksz:key size,key 的大小
- value_sz:value size,value 的大小
- key:用户实际存储的 key
- value:用户实际存储的 value
每次写入都是追加写到活跃文件当中,删除操作实际上也是一次追加写入,只不过写入的是一个特殊的墓碑值,用于标记一条记录的删除,也就是说不会实际去删除某条数据。当执行 merge 操作的时候,才会将这种无效的数据清理掉。
所以 bitcask 模型中,一个文件中的数据,实际上就是多个具有固定格式的数据集合的排列:

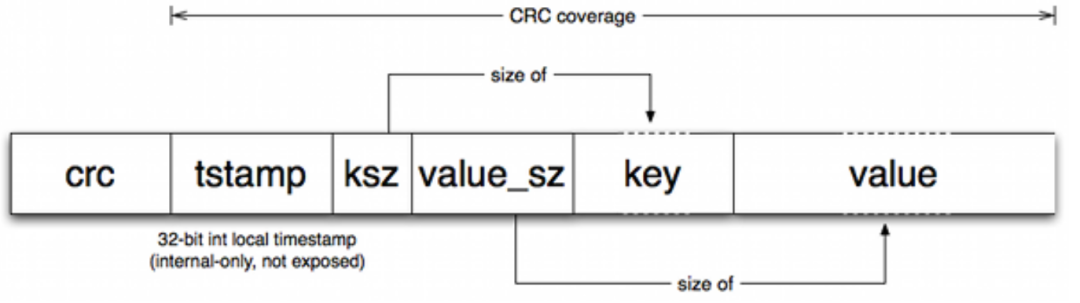
在追加写入磁盘文件完成后,就会更新内存中的数据结构,论文中叫做 keydir,实际上就是全部 key 的一个集合,存储的是 key 到一条磁盘文件数据的位置,这里论文中说的是使用一个哈希表来存储。
keydir 一定会存储一条数据在磁盘中最新的位置,这样数据更新之后,文件中旧的数据仍然存在,等待 merge 的时候被清理。
所以读取数据就会变得很简单,首先根据 key 从内存中找到对应的记录,这个记录存储的是数据在磁盘中的位置,然后根据这个位置,找到磁盘上对应的数据文件,以及文件中的具体偏移,这样就能够获取到完整的数据了。
由于旧的数据实际上一直存在于磁盘文件中,因为我们并没有将旧的数据删掉,而是新追加了一条标识其被删除的记录。
所以随着 bitcask 存储的数据越来越多,旧的数据也可能会越来越多。论文中提出了一个 merge 的过程来清理所有无效的数据。
merge 会遍历所有不可变的旧数据文件,将所有有效的数据重新写到新的数据文件中,并且将旧的数据文件删除掉。
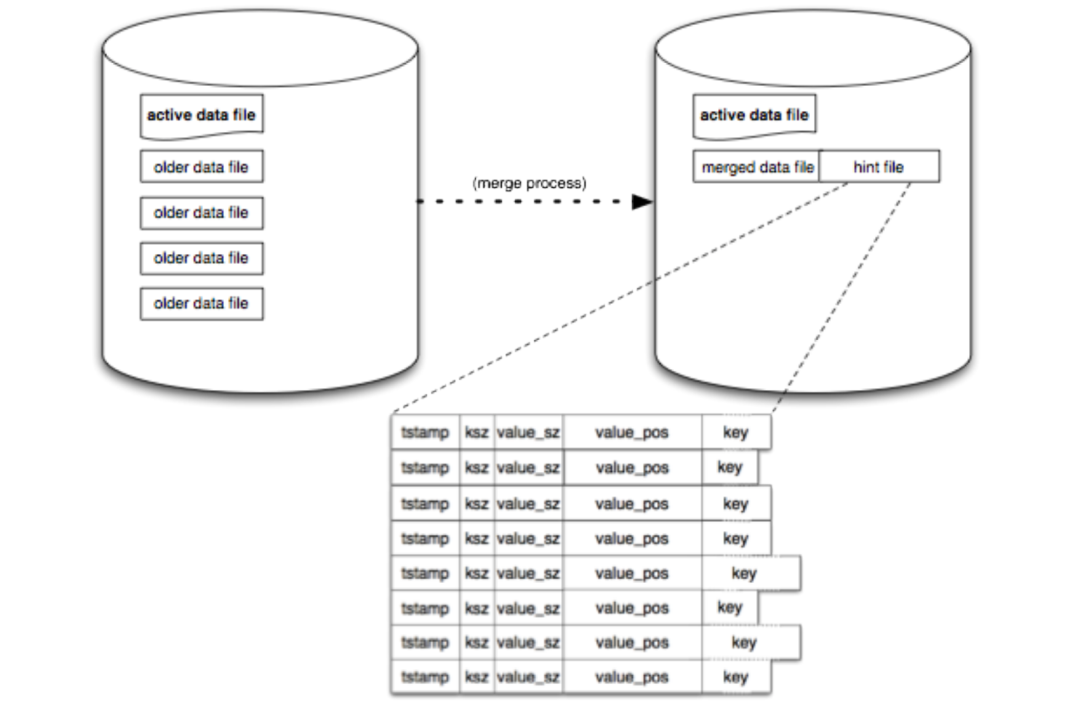
merge 完成后,还会为每个数据文件生成一个 hint 文件,hint 文件可以看做是全部数据的索引,它和数据文件唯一的区别是,它不会存储实际的 value。
它的作用是在 bitcask 启动的时候,直接加载 hint 文件中的数据,快速构建索引,而不用去全部重新加载数据文件,换句话说,就是在启动的时候加载更少的数据去构建索引,因为 hint 文件不存储 value,它的容量会比数据文件更小。
和 LSM Tree 的联系与区别
Bitcask 和 LSM Tree 都采用了日志追加写入的方式,只不过在实现上,bitcask 更像是简化版的 LSM Tree。
LSM Tree 的主要的结构有 WAL 预写日志、Memory Table、SSTable,预写日志也是追加进行写入,其复杂度主要在于对 SSTable 的维护以及 Compaction。
Bitcask 大致相当于 LSM Tree 中的 wal+memtable,只不过有一个很关键的区别: LSM Tree 的 memtable 存储的是还没有来得及刷到 SSTable 中的 key/value 数据,而 bitcask 中的 memtable 存储的是全量的 key+索引信息;而且 LSM Tree 的 memtable 存在多个,而 bitcask 可以认为只有一个。
LSM Tree 的优势是什么?
LSM Tree 的写入快速,能够处理远超内存容量的数据,但是如果刷 SSTable 的后台任务不及时,可能会造成写限速(Write Stall),并且在读取的时候,在 SSTable 中可能会存在多次磁盘 IO 寻址。
Bitcask 的优势是什么?
Bitcask 最大的优势在简单、易维护、读写稳定快速,读写不受数据量的限制,无论数据量大小,写永远都是一次追加写文件和一次更新内存索引,读也永远都是从内存中读取索引,然后直接一次磁盘文件寻址。
这种优势是维护全量内存索引带来的,但这同时带来了一个弊端,那就是在重启的时候必须加载全量数据去构建索引,数据集大的情况下,重启时间可能会很长,这种情况下 bitcask 模型适合处理较小规模的数据集。
bitcask 的文件清理主要通过扫描数据并重写来完成,这比 LSM Tree 的 Compaction 流程简单得多。
以上就是 bitcask 存储模型的基本原理,也是 rosedb 的基本架构。
但是在具体的实现当中,也有两点关键的区别。
第一点是,bitcask 论文中提到使用一个哈希表作为内存索引数据结构,但目前在 rosedb 当中使用的是 Google 开源的 BTree 实现。其实这里使用任意一个内存数据结构都是可以的,可以根据实际的需求和场景来确定或者进行扩展。
第二点是,针对数据文件的内部组织结构,rosedb 的 wal 实现采用了 block 分块的方式,这是原 bitcask 论文中未提及到的。
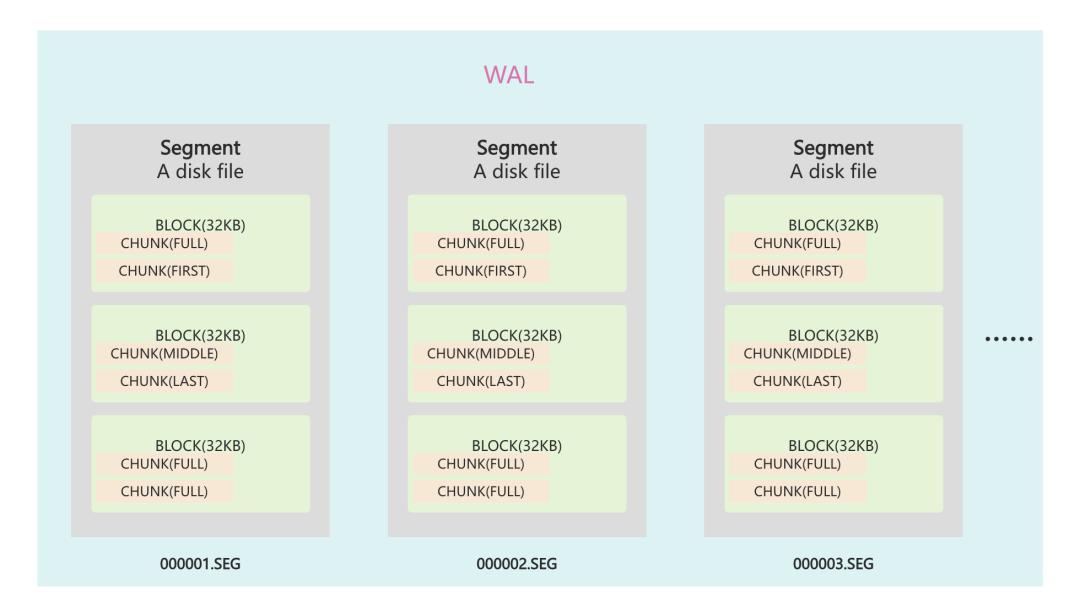
当然还有一些其他具体实现时候的魔鬼细节,将会在后续的文章中为大家一一揭晓。
广告区:
《从零实现 KV 存储》,使用 Rust 和 Go 两种语言实现,手把手教学,只需要基础的语法知识,即可学会一个硬核实战项目!
《从零实现 SQL 数据库》,使用 Rust 手写一个数据库系统,超级硬核,Rust 实战项目首选!