预写日志,即 Write Ahead Log(wal),是一种数据库系统中常见的用于崩溃恢复的技术保障。例如在 Postgres 中,也有对应的 wal 实现,主要是为了防止系统崩溃时数据丢失,因为在 Postgres 中,为了写入效率,数据一般会先写入到内存中的 shared buffer 中。
如果 buffer 中的数据还没有来得及刷到磁盘,此时发生了系统崩溃等其他严重错误,那么会导致数据丢失。所以常见的解决方式是在写入到 buffer 之前,会先将数据写入到 wal 中,这样就能够保证数据的可靠性。
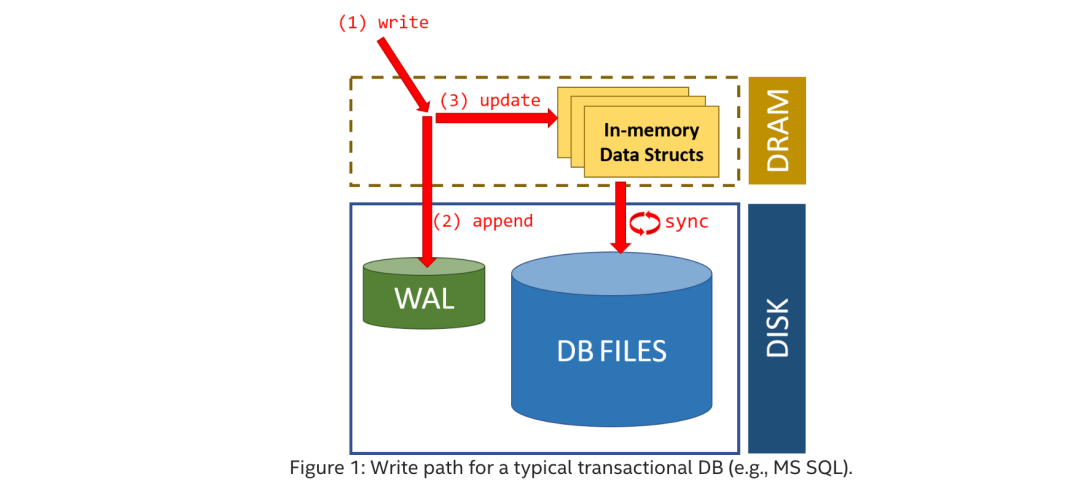
并且在数据库系统中,wal 也被用作事务完整性的技术保证,确保事务的原子性(A),以及持久性(D),只有事务的修改完全写入到 wal 文件中才能够被正确的提交,如果事务中发生了一些错误,那么在重启的时候,会通过重放日志的方式来让数据库达到一致的状态。
有一篇论文专门讲述了 wal 在数据库系统中对事务的保障,感兴趣可以参考:https://cs.stanford.edu/people/chrismre/cs345/rl/aries.pdf
wal 文件是采用 append only 的方式进行写入,也就是说这个文件的写入永远只能追加写入,而不会去修改其中的某一部分数据。这样做的目的的是利用顺序 IO 的性能优势,特别是在传统的 HDD 磁盘上,顺序 IO 和随机 IO 存在较大的性能差异。
具体到 rosedb 中的 WAL 预写日志,其实设计上也比较的简单。
rosedb 中的 wal 作为一个单独的组件,独立于 rosedb 之外,并且也是开源的
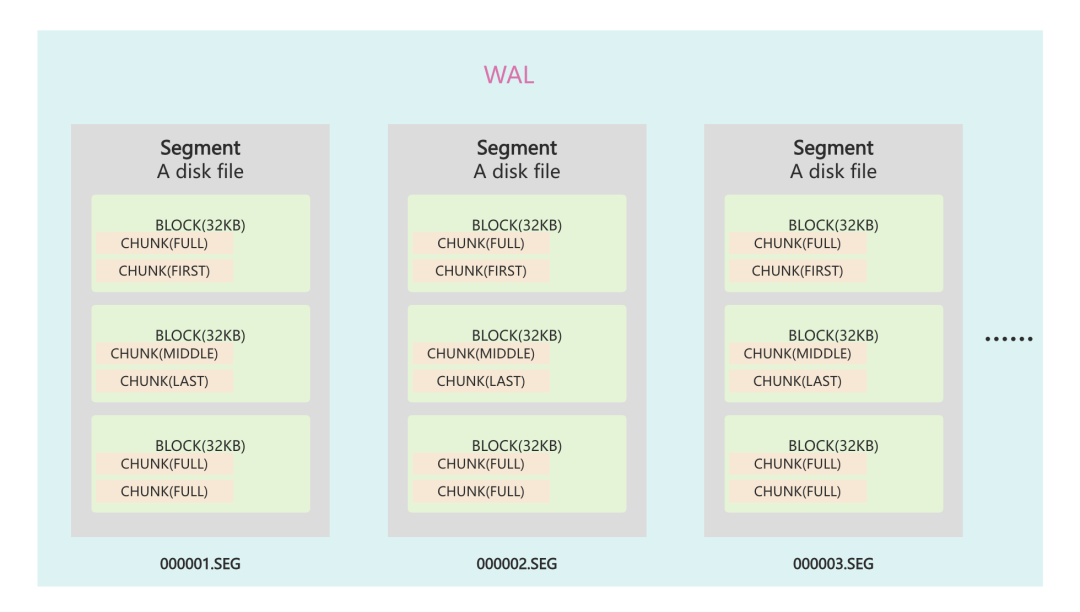
rosedb 的 wal 设计和实现基本参考了 RocksDB 中预写日志的实现,文件组织格式基本一致。
可以参考 RocksDB 的对应文档:https://github.com/facebook/rocksdb/wiki/Write-Ahead-Log-File-Format
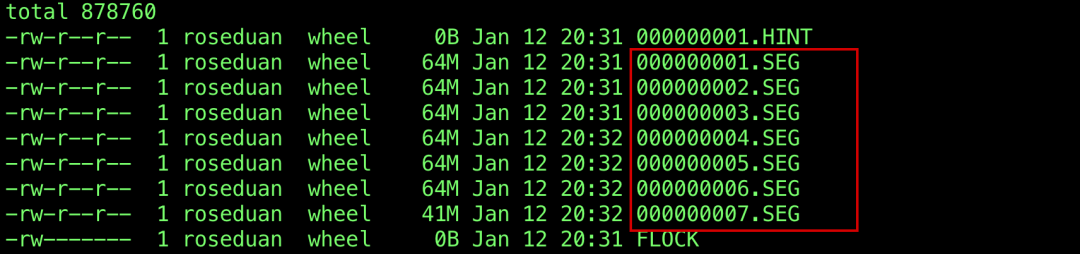
在 wal 当中将每个文件叫做一个 Segment,一个 Segment 文件一般会有一个阈值,比如 512MB、1G、2G 等等,可以在打开时根据 Option 参数进行配置。
写到了阈值之后,就会关闭旧的文件然后打开一个新的文件,文件名也一般是递增的,大致如下:
每一个 Segment 文件的内部,实际上是切分成了 N 个 32 KB 的连续 Block。
这时候大家可能会有一个疑问,为什么需要将文件切分成 32 KB 的 block 呢?
一个最主要的原因是提升文件读写的效率,例如在读数据的时候,如果不分 block,那么写入了 10 条数据,在读取的时候,需要通过十次系统调用 read 才能够将数据读取出来。我们知道系统调用需要从用户态切换到内核态,这存在一定的性能开销。
如果是分 block 的方式,一次性将 32 KB 的数据全部读取出来,效率会得到大幅提升。这里对 block 取值是 32KB 其实也是参考了 RocksDB 的做法,其实 16KB 或者是 64KB 理论上也是可以的。
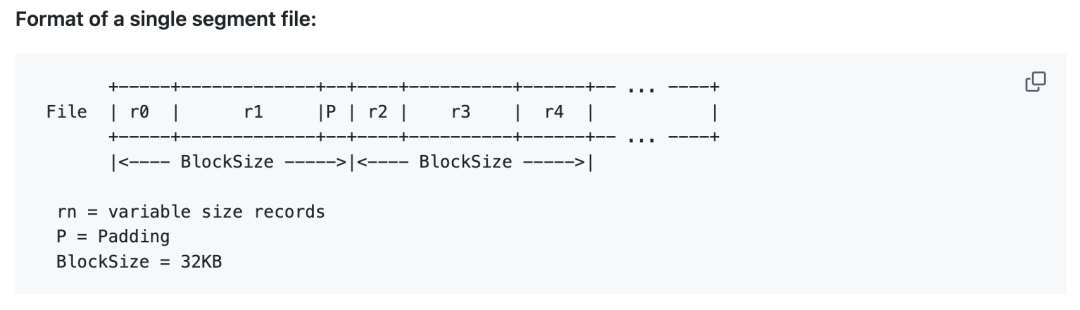
向 wal 文件中写入的一条日志数据,一般叫做 Chunk,chunk 数据是有固定格式的:
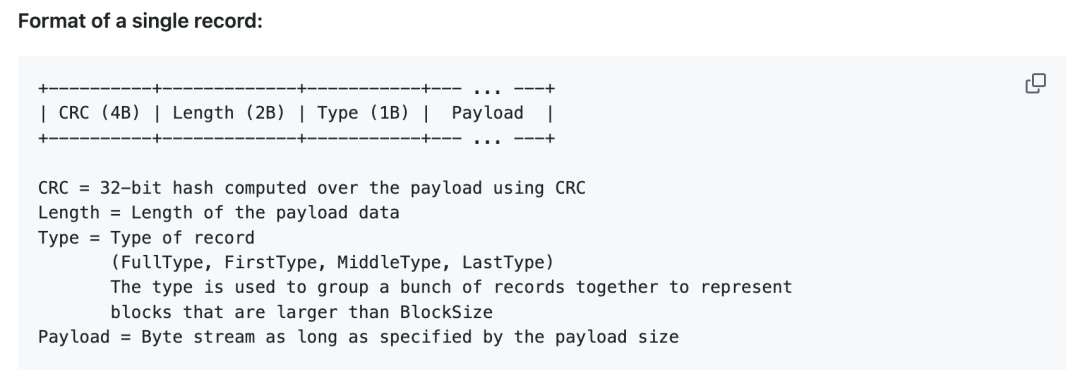
前 7 个字节是固定的 header 部分,主要是
- CRC 校验和,占 4 字节
- 实际存储的数据长度,占 2 字节
- Chunk 类型,分为了 FULL、FIRST、MIDDLE、LAST,占 1 字节
最后的 payload 部分就是实际存储的数据,当然这是变长的,实际的长度记录在前面固定的 header 当中。
在写入 Chunk 的时候,根据当前 block 的容量和 chunk 的大小,分为了两种情况:
- Chunk 能够完全容纳到当前 block 中,那么这个 Chunk 类型是 FULL
- Chunk 不能够完全容纳到 block 中,则需要将 Chunk 进行切分,第一部分是 FIRST,中间的部分是 MIDDLE、最后的一部分是 LAST
下面举几个具体的例子:
假如当前 block 还剩余 10 KB 的空间,当前 chunk 的大小是 1 KB,那么能够完全容纳到这个 block 中,那么写入的时候会标识这个 chunk 的类型是 FULL。
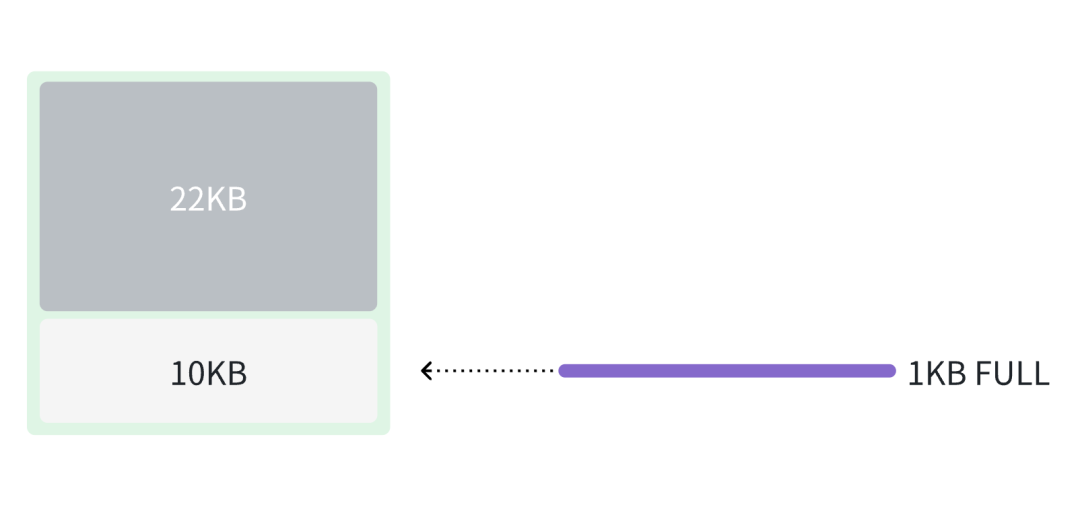
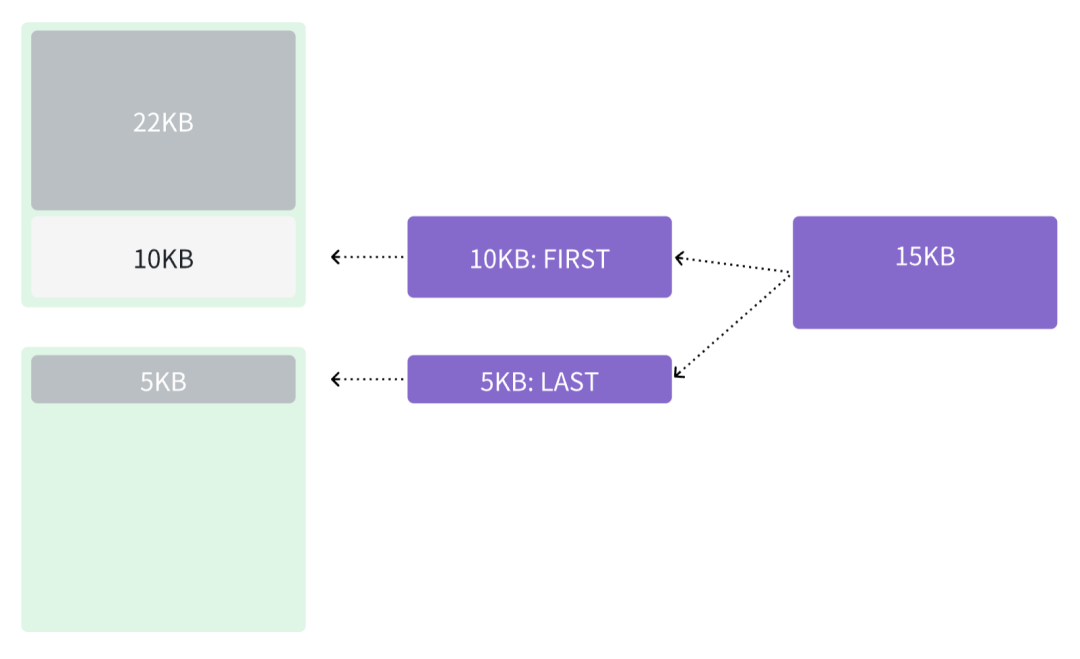
如果 chunk 的大小是 15 KB,那么需要将 10KB 存储到当前 block,标识其类型是 FIRST,剩余的 5 KB 存储到下一个 block 中,类型是 LAST。
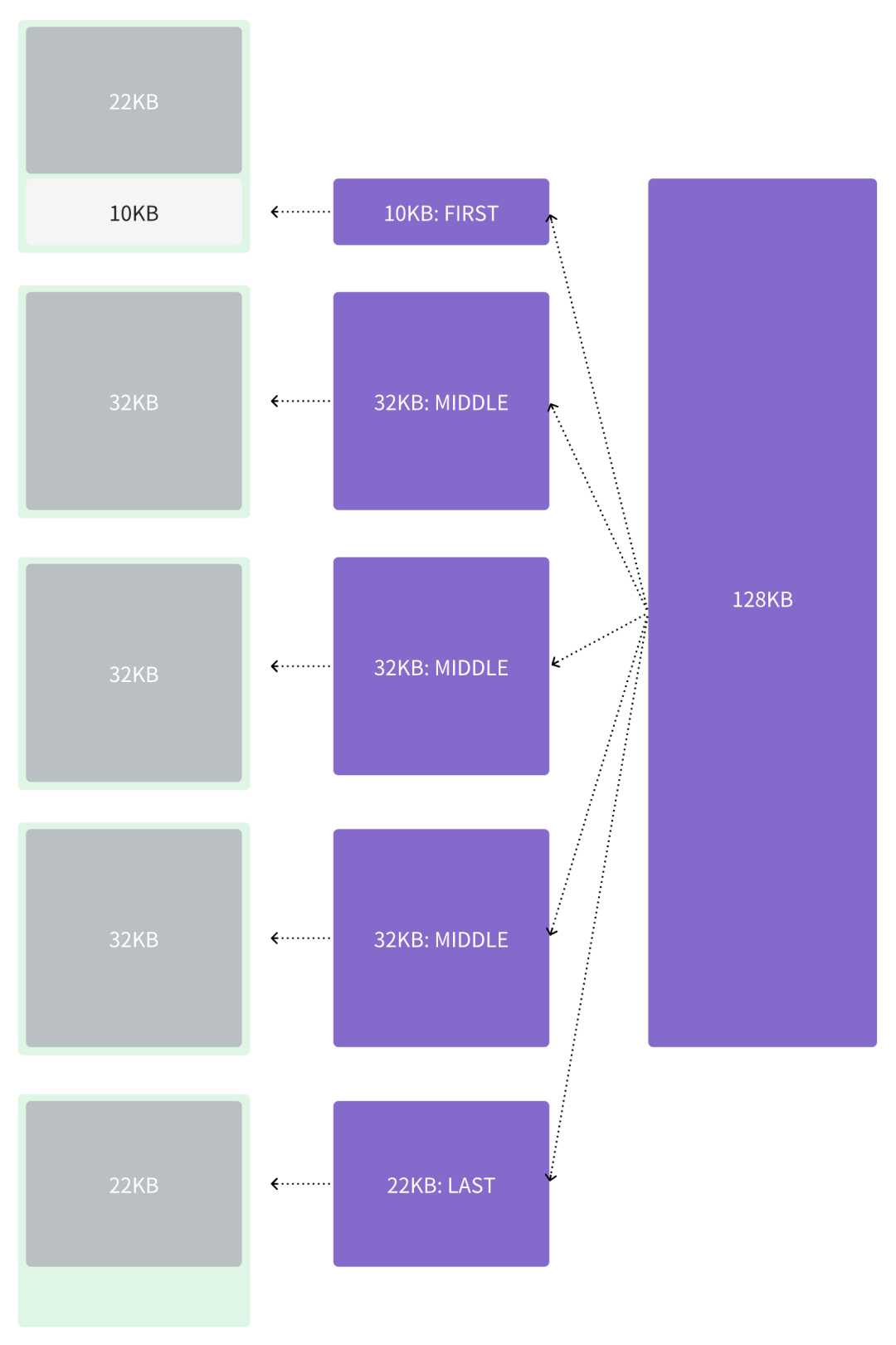
当然还有一种情况是,chunk 更大,例如是 128 KB,那么 10 KB 会存储到当前 block 中,类型是 FIRST,剩余的 118 KB仍然无法存储到一个 block 中,所以需要继续切分,将其切分为 4 个 chunk,前 3 个 chunk 占据一个完整的 block 大小,3 * 32 = 96 KB,这三个 chunk 的类型就是 MIDDLE。
最后还剩 118 - 96 = 22 KB,再将其存储到一个 block 中,这是完整数据的最后一部分,所以类型是 LAST。
在读取的时候,如果 chunk 的类型是 FULL,则说明是一条完整的数据。
如果 chunk 的类型是 FIRST,那么需要继续读取下一个 chunk,直到读到类型为 LAST 的 chunk,将这一部分数据组合起来,才是最终完整的数据。
能够搞懂这几个示例,其实理解 wal 就非常的容易了,wal 的设计是 rosedb 最核心的一个部分,是学习和理解 rosedb 最重要的前置内容,下一节将详细讲解 wal 的代码,帮助理解这个组件在代码实现上的细节。
广告区:
《从零实现 KV 存储》,使用 Rust 和 Go 两种语言实现,手把手教学,只需要基础的语法知识,即可学会一个硬核实战项目!
《从零实现 SQL 数据库》,使用 Rust 手写一个数据库系统,超级硬核,Rust 实战项目首选!