上篇文章我们说了,AI Agent 的本质就是三样东西:LLM + 工具 + 循环。
LLM 负责思考,这个好理解,循环我们后面再聊,今天先说中间那个——工具。
为什么要先说工具?因为它是 Agent 和普通聊天机器人之间最关键的分水岭。没有工具,LLM 再聪明也只是一个"嘴强王者"——说得头头是道,但啥也干不了。
LLM 的困境
你有没有想过,LLM 为什么不能直接帮你干活?
原因很简单:LLM 本质上就是一个文本生成器。
你给它一段话,它给你回一段话,仅此而已。它不能读你电脑上的文件,不能执行命令,不能访问互联网,更不能帮你改代码然后保存——它和你的电脑之间,隔着一道墙。
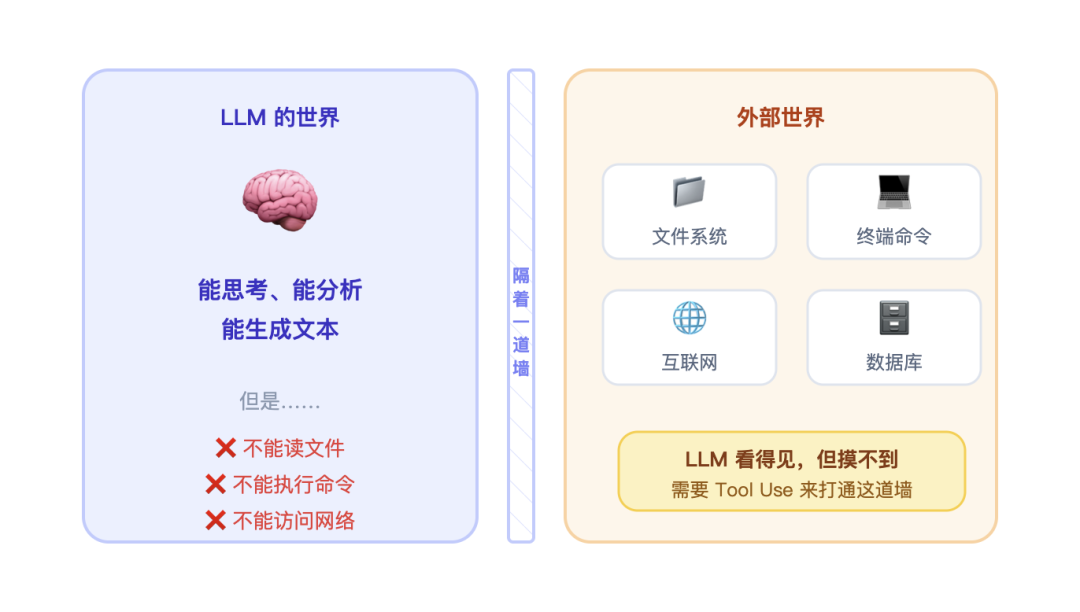
你跟 ChatGPT 说"帮我把 main.py 第 42 行的 bug 修一下",它可以告诉你怎么改,但它没办法真的打开你的文件改掉它。就像一个被关在玻璃房里的天才,看得见外面,但摸不到。
所以问题来了:怎么让 LLM 能够和外部世界交互?
答案就是 Tool Use(工具使用)。
什么是 Tool Use
Anthropic 在 Claude 的官方文档中对 Tool Use 的描述非常清晰,我直接借用他们的说法:
Tool Use 允许 Claude 与外部工具和 API 进行交互。你在 API 请求中定义工具,Claude 会在合适的时候决定调用哪个工具、传什么参数,你的代码负责执行工具并返回结果。
说白了就是四个角色的协作:你(用户)提需求,Agent 程序做中间人,LLM 做决策,工具来执行。
具体怎么运作?按照 Anthropic 官方的说法,整个流程分成四步:
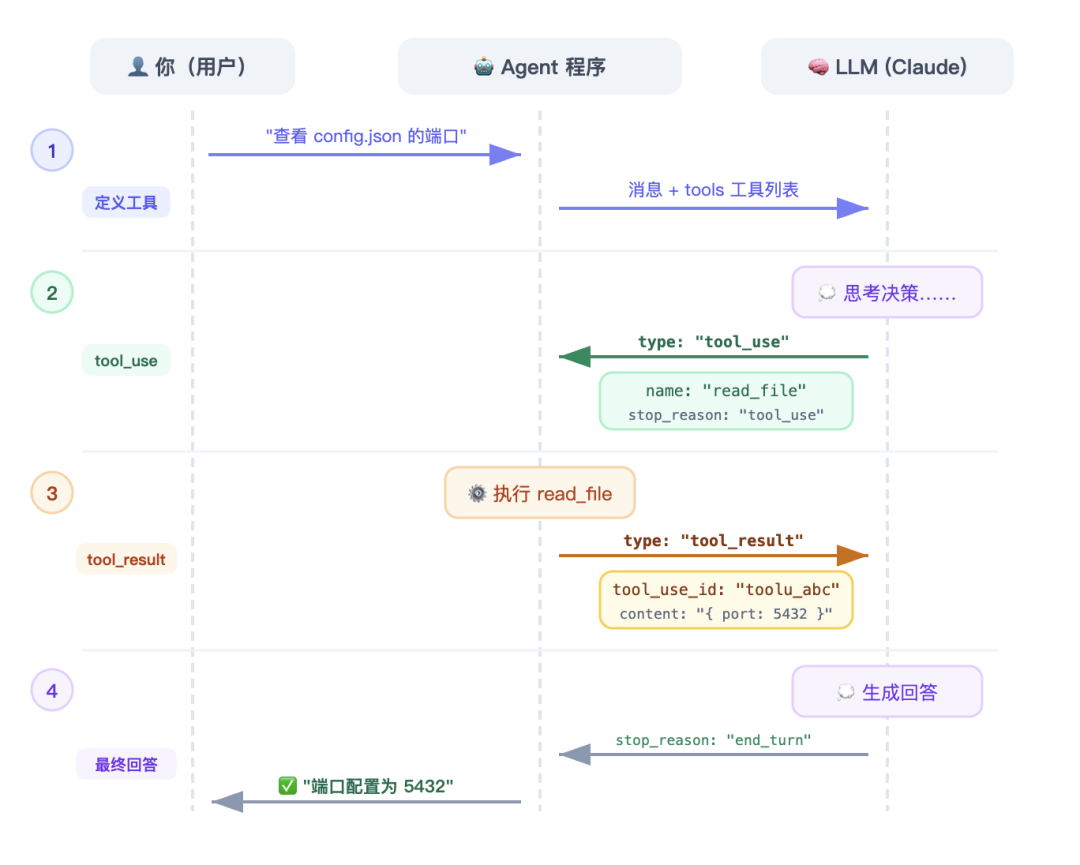
第一步:定义工具,发送请求
在你调用 LLM API 的时候,除了发送用户的消息,你还需要在请求里带上一个 tools 数组,告诉 LLM:“你现在有这些工具可以用。”
每个工具的定义包含三个要素:name(名字)、description(描述)、input_schema(参数定义,用 JSON Schema 格式)。
比如定义一个读文件的工具:
| |
这就是在给 LLM 一份"菜单":你有一个能力叫 read_file,作用是读文件,需要一个参数 file_path。
这里的 description 特别重要。LLM 就是靠这个描述来判断什么时候该用这个工具的。描述写得越清晰,LLM 的调用就越准确。
第二步:LLM 返回 tool_use
LLM 拿到用户的任务和工具列表后,会思考:这个任务我自己能回答吗?还是需要借助工具?
如果它决定要用工具,返回的内容里会包含一个类型为 tool_use 的内容块。
这是 Anthropic API 里的专有概念——LLM 的回复不再只是纯文本,而是一个结构化的工具调用请求:
| |
注意这里有个 id 字段,每次工具调用都有一个唯一标识,后面返回结果的时候要用到它。
这里最关键的一点——LLM 并没有真的去读文件。它只是"说"了一句话:我想读 src/main.py 这个文件。
就像你在餐厅点菜,你说"来一份宫保鸡丁",但你不会自己跑到厨房去炒,LLM 就是那个点菜的人。
同时,API 响应里的 stop_reason 会变成 “tool_use”,而不是正常回复时的 “end_turn”。
Agent 程序就是靠这个标志来判断:LLM 还没说完,它想调工具,我得帮它执行。
第三步:执行工具,返回 tool_result
真正干活的是你写的 Agent 程序。它解析出 LLM 想调的工具和参数后,去执行对应的操作——比如真的去读那个文件,拿到文件内容。
然后,把结果用 tool_result 的格式返回给 LLM:
| |
看到那个 tool_use_id 了吗?它和前面第二步的 id 是对应的,这样 LLM 就知道这是哪次工具调用的结果。
如果工具执行出错了呢?你可以在返回时加上 “is_error”: true,告诉 LLM:这个工具调用失败了,你得换个思路。
第四步:LLM 拿到结果,继续思考
LLM 拿到 tool_result 后,就可以基于这些信息继续思考。它可能直接生成最终回复,也可能决定再调用其他工具——比如读完文件后觉得还要搜一下某个函数的引用。
这就自然引出了下一篇要讲的 Agent Loop:工具调用可以反复进行,形成一个循环,直到 LLM 觉得任务完成了为止。
用一个例子串起来
我们来看一个具体的例子,把四步完整走一遍。假设你对 Agent 说:
“帮我看看 config.json 里数据库的端口配置是多少。”
你 → Agent:“帮我看看 config.json 里数据库的端口配置是多少。”
Agent → LLM:把你的消息 + tools 工具列表一起发给 Claude API。
Claude 思考:用户想知道 config.json 的内容,我需要先读这个文件。我有 read_file 这个工具可以用。
Claude → Agent:返回 tool_use 内容块,stop_reason: “tool_use”
| |
Agent 执行:真的去读 config.json,拿到内容。
Agent → Claude:返回 tool_result
| |
Claude 思考:拿到了,端口是 5432,可以直接回答用户了。
Claude → Agent → 你:“config.json 中数据库端口配置为 5432。“此时 stop_reason: “end_turn”,Agent 知道 LLM 说完了,循环结束。
看,整个过程中 LLM 做的事情就是两件:判断该用什么工具,以及根据工具返回的结果生成回答。它自己不执行任何操作,所有的"脏活累活"都是 Agent 程序在干。
以前不是这样的
你可能觉得这套机制很自然,但其实 Tool Use 是最近两年才成熟起来的。
早期的 LLM 根本没有原生的工具调用能力。那时候想让 LLM 调工具,靠的是什么?Prompt hack。
什么意思呢?就是你在 System Prompt 里写一大段话,告诉 LLM:
“如果你需要搜索,请按以下格式输出:
关键词*,我会帮你执行搜索并返回结果。”*
然后你的程序去解析 LLM 输出的文本,看有没有这个特定格式的标签,有的话就提取出来执行。
这种方式问题很大。LLM 生成的文本格式经常不对,漏个引号、多个换行就解析失败了。而且不同的工具要定义不同的格式,维护起来很痛苦。
现在不一样了,Anthropic 和 OpenAI 都在 API 层面原生支持了 Tool Use。工具定义用标准的 JSON Schema,LLM 返回结构化的 tool_use 内容块,格式稳定、解析简单。不再需要任何文本解析的 hack。
这一步的进化看起来不起眼,但它让 Agent 的可靠性提升了一个量级。可以说,没有原生 Tool Use 支持,就没有今天的 Agent 生态。
Coding Agent 需要哪些工具
工具这个概念很通用,不同场景的 Agent 用的工具完全不同。做客服的 Agent 可能需要查订单、查库存的工具,做数据分析的 Agent 可能需要查数据库、画图表的工具。
对于 Coding Agent——也就是帮你写代码的 Agent——核心工具其实就那么几个:
Read File:读取文件内容。Agent 要改你的代码,总得先看看现在长什么样吧。
Write File:写入或修改文件。看完了,想好了,得能动手改。
Bash:执行终端命令。跑测试、装依赖、查看 git 状态,都靠它。
Search:搜索代码。在大型项目里快速定位某个函数、某个变量在哪里用到了。
就这四个,一个 Coding Agent 的基本能力就全了。Cursor、Claude Code 这些产品,核心工具也就是这些,只不过在此基础上做了更多的细节优化和体验打磨。

你可能会觉得:就这?对,就这。工具不需要多复杂,关键是 LLM 要知道什么时候该用哪个、怎么用。而现在的模型,在这方面已经做得非常好了。
一句话总结
Tool Use 就是给 LLM 一份工具菜单,让它来点菜,Agent 程序负责上菜。LLM 不直接执行任何操作,它只负责决策。
理解了这一点,你就掌握了 Agent 的第二个核心概念。
下一篇,我们来聊最后一个核心——Agent Loop。有了工具,怎么把它们串成一个自动化的工作流,让 Agent 能一步步把任务搞定?这就是循环的魅力了。